زمانی یک مطالعه روا است که بتواند هدف
مورد نظر را اندازه گیری نماید و همچنین در طرح مطالعه، خطای منطقی وجود نداشته باشد.به عبارت دیگر این تعریف به دو جنبه اساسی از روایی اشاره می کند که عبارتند از: قابلیت اندازه گیری هدف (اعتبار درونی) و طراحی صحیح مطالعه از جوانب مختلف (اعتبار بیرونی) .
1- اعتبار درونی :در روایی درونی قابلیت ابزار مورد نظر در اندازه گیری هدف ارزیابی می شود.انواع روایی درونی یک تحقیق عبارتند از روایی سازه ای، محتوایی، همزمان و پیش بین .
در برخی منابع دو نوع روایی همزمان و پیش بین در یک گروه و تحت عنوان روایی ملاکی معرفی می شود. برخی از مؤلفین نیز بیان می کنند که تنها یک نوع از روایی یعنی روایی سازه ای وجود دارد و روایی ملاکی و محتوایی زیر بخش هایی از آن است.با توجه به اهدافی که هریک از انواع روایی دنبال می کنند، در عمل ارزیابی همزمان هر چهارنوع روایی کار مشکلی است و اغلب پژوهشگران تنها دو نوع روایی محتوایی و سازه ای را ارزیابی می کنند.
1-1.روایی محتوایی(Content Validity): هدف از این نوع ارزیابی پاسخ به این سؤال است که آیا محتوای ابزار قابلیت اندازه گیری هدف تعریف شده را دارد یا خیر؟ به عنوان مثال آیا محتوای آزمونی که برای اندازه گیری افسردگی تعریف شده است، واقعا افسردگی را اندازه می گیرد.به همین دلیل برای ارزیابی روایی محتوایی از قضاوت افراد خبره در زمینه تخصصی مورد نظر استفاده می شود. برای مثال برای ارزیابی افسردگی ، پس از لیست نمودن تمام نشانه هایی که افسردگی را ارزیابی می کند از طریق ادبیات موضوع ، می توان مرتبط بودن، سادگی ووضوح هریک از آیتم ها و همچنین ضروری بودن آن ها را در قالب پرسشنامه ای از متخصصان مربوطه پرسید.
1-1-1) نحوه ارزیابی روایی محتوایی(محاسبه CVI وCVR)
برای ارزیابی روایی محتوایی از نظر متخصصان در مورد میزان هماهنگی محتوای ابزار اندازه گیری و هدف پژوهش ، استفاده می شود. برای این منظور دو روش کیفی و کمی در نظر گرفته می شود. در بررسی کیفی محتوا پژوهشگر از متخصصان درخواست می کند تا پس از بررسی کیفی ابزار ، بازخورد لازم را ارائه دهند که براساس آن موارد اصلاح خواهند شد.
برای بررسی روایی محتوایی به شکل کمی، ازدو ضریب نسبی روایی محتوا (CVR) و شاخص روایی محتوا (CVI)، استفاده می شود. برای تعیین CVR از متخصصان درخواست می شود تا هرآیتم را براساس طیف سه قسمتی«ضروری است» ، «مفید است ولی ضرورتی ندارد» و «ضرورتی ندارد» بررسی نماید. سپس پاسخ ها مطابق فرمول زیر محاسبه می گردد.
")
در این رابطه n_E تعداد متخصصانی است که به گزینه ی ضروری پاسخ داده اند و N تعداد کل متخصصان است. اگر مقدار محاسبه شده از مقدار جدول بزرگتر باشد اعتبار محتوای آن آیتم پذیرفته می شود.
1-1-2) روایی صوری زیر بخشی از روایی محتوایی
این نوع ارزیابی شامل این موضوع می شود که آیا ظاهر ابزار به صورت مناسب برای ارزیابی هدف مورد نظر طراحی شده است یا خیر؟در اینجا نیز از نظر متخصصان برای تعیین روایی صوری استفاده می شود. در تعیین کیفی روایی صوری موارد سطح دشواری ، میزان عدم تناسب و ابهام مورد بررسی و اصلاح قرار می گیرد.در گام بعدی برای کاهش و حذف آیتم های نامناسب و تعیین اهمیت هریک از آیتم ها از روش کمی تأثیر آیتم استفاده خواهد شد. در این روش به هریک از گزینه های آیتم مورد نظر بنا به تعداد آنها اعداد 3،2،1،... اختصاص داده شده و فراوانی مربوط به هر یک را نیز محاسبه کرده، از رابطه ی زیر استفاده می نماییم.شماره گزینه * (%)فراوانی= شاخص
چنانچه این شاخص بیش از 1.5 باشد، آیتم برای تحلیل های بعدی مناسب تشخیص داده می شود.
1-2. روایی ملاکی (روایی همزمان و پیش بین)
منظور از روایی ملاکی میزان همبستگی بین نمرات حاصل از یک ابزار با نمرات حاصل از ابزار اندازه گیری دیگر (ملاک) است. گاهی ارزیابی همبستگی به منظور پیش بینی برای آینده است، یعنی نمرات ابزار ملاک پس از گذشت یک فاصله زمان از اجرای ابزار اول گردآوری خواهد شد در اینصورت به آن روایی پیش بینی گفته می شود. زمانی که این پیش بینی بدون فاصله و در زمان حال انجام شود، به آن روایی همزمان می گویند. برای نعیین روایی ملاکی ضریب همبستگی بین نمرات حاصل از دو ابزار به عنوان شاخص روایی آزمون مورد نظر محاسبه شده و هر چه این ضریب بزرگتر باشد، ابزار روایی بیشتری دارد.
1-3. روایی سازه ای (Construct validity)
گفت روایی سازه ای این موضوع را بررسی می کند که آیا اجزای مقیاس مورد نظر توانایی تشکیل مقیاس را دارند یا برخی از آن ها نامرتبط اند. این نوع روایی اغلب روایی عاملی نیز نامیده می شود و دلیل آن نیز نحوه ی ارزیابی این نوع روایی با روش های تحلیل عاملی است.سازه ی نامناسب سازه ای است که توافق نظری در محتوای آن وجود ندارد.
روایی سازهای به دو دسته روایی همگرایی و روایی افتراقی تقسیم می شود.
1-3-1) روایی همگرایی : روایی همگرایی به همگرایی (همسو بودن یا همبستگی) آیتم های تشکیل دهنده یک مقیاس اشاره دارد. این نوع روایی به صورت های زیر قابل اندازه گیری است ، 1) با بررسی همبستگی بین آیتم های سازنده مقیاسکه در واقع همسانی درونی آیتم ها نامیده می شود ارزیابی می شود. همسانی درونی به کمک آلفای کرونباخ، ساختار سازه ی عاملی ، مدل راش، متوسط واریانس بیان شده و واریانس روش مشترک قابل محاسبه است. 2) همسانی بین مقیاس مورد بررسی با ابزارهای مشابهی که برای اندازه گیری سازه ی مورد نظر طراحی شده اند. در صورت وجود همبستگی قوی بین سازه ی هدف و سازه ی موجود دیگر، نیازی به تعریف سازه ی جدید نیست.
3) همبستگی بین سازه ی مورد نظردر روش های مختلف(نمونه ی هدف و نمونه ارزیابی اعتبار) محاسبه شود. اگر این همبستگی مقدار قابل توجهی داشته باشد، روایی آن تأیید می شود.
در ادامه به معرفی همسانی درونی آیتم ها و روش های محاسبه آن می پردازیم.
1-3-2. روایی افتراقی
این بخش از روایی سازه ای به این موضوع اشاره دارد که آیتم های مربوط به سازه های مختلف به صورتی بسیار قوی با یکدیگر همبستگی نداشته باشند تا براساس آن بتوان نتیجه گرفت که دو سازه یک هدف را اندازه گیری میکنند.این موضوع زمانی رخ می دهد که بین دو سازه به لحاظ تعریف هم پوشانی وجود داشته باشد.برای ارزیابی این روایی ازروشهای همبستگی ، تحلیل عاملی ،متوسط واریانس بیان شده ورویکرد چندسازه ای-چند روشی استفاده می شود.
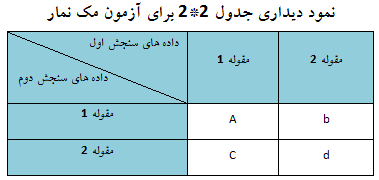
1) ارزیابی مبتنی بر همبستگی: هنگامی که یکی از آیتم های یک مقیاس باآیتم های مقیاس دیگری، که در مطالعه پژوهشگر حضور دارند، همبستگی بالایی داشته باشند(r>0.85 به عنوان یک قاعده سرانگشتی)، هشداری مبنی بر همپوشانی داشتن این دو سازه خواهد بود.
2) روش تحلیل عاملی اکتشافی : در یک تحلیل عاملی اکتشافی دو سازه در صورتی از هم افتراق دارند که دو مقیاس مختلف، دو مجموعه از بارهای عاملی متفاوت را ایجاد نمایند.
3) روش متوسط واریانس بیان شده : این روش یک روش جایگزین مبتنی بر تحلیل عاملی است که توسط فورنل وولاکر(1981) ارائه شد. در این روش زمانی بین دو سازه افتراق وجود دارد که متوسط واریانس بیان شده برای یک سازه بزرگتر از واریانس مشترک بین آن ها باشد.برای این منظور از ماتریسی استفاده می شود که از توان دوم کواریانس بین هر مقیاس با سایر مقیاس ها تشکیل شده است. برای بررسی روایی عناصر قطر اصلی ماتریس با شاخص AVE که به صورت زیر تعریف می شود، جایگزین می شود،
")
s_1=مجموع توان های دوم بارهای عاملی مربوط به آیتم های سازنده مقیاس
s_2= مجموع مربوط به تمام آیتم ها برای شاخص (توان دوم بارهای عاملی -1 )
زمانی روایی افتراقی تأیید می گردد که هریک از عناصر روی قطر اصلی نسبت به هر مؤلفه دیگر روی سطر یا ستون بزرگتر باشد.
4) روش تحلیل عاملی تأییدی:در این روش از تحلیل عاملی تأییدی بدین صورت استفاده می شود که اگر به ازای مسیرهای تعریف شده مبتنی بر مبانی نظری برای ارتباط بین آیتم ها و سازه ی تشکیل دهنده ی آن، شاخص های برازش مدل مقادیر مناسبی داشته باشند، روایی افتراقی سازه های تعریف شده در این تحلیل تأیید می گردد.
5) استراتژی چندروشی-چند سازه ای: در این روش چند سازه تعریف می شود (چند سازه ای) و این سازه ها از طریق چند منبع جمع آوری می شود (چند روشی).به عنوان مثال در ارزیابی کیفیت زندگی کودکان از طریق پرسشنامه هریک از جنبه های کیفیت زندگی از طریق چند زیرسازه و از طریق منیع کودکان و والدین جمع آوری می گردد. هنگامی که بین سازه های اندازه گیری شده در هر روش همبستگی کوچکی وجود داشته باشد رواییافتراقی سازه ها تأیید می شود.
1-3-3 . ارزیابی روایی سازه ای با استفاده از تحلیل عاملی اکتشافی
روش تحلیل عاملی یا تجزیه ی عامل ها این امکان را برای محققان فراهم می آورد که از بین متغیرهای زیاد و روابط پیچیده میان آن ها به الگوی مشخصی دست یابند. تحلیل عاملی اکتشافی بر قاعده ی مهمی تأکید دارد، که برخی از عامل های اصلی مسئول هم تغییری میان متغیرها هستند.از جمله اهداف تحلیل عاملی اکتشافی می توان به تعیین ابعاد ابزار ، هنجاریابی پرسشنامه ها یا آزمون ها ، کاهش ابعاد (از متغیرها به عامل ها) ، ارزیابی همسانی و افتراق در بحث روایی سازه ای.
2- اعتبار بیرونی : اعتبار بیرونی با این امر سروکار دارد که آیا نتایج به دست آمده قابل تعمیم به گروهی مشابه گروه مورد مطالعه یا گروهی بزرگتر هست یاخیر .ممکن است اعتبار درونی یک تحقیق در حد مطلوبی باشد ولی این بدان معنی نیست که تحقیق انجام شده دارای اعتبار بیرونی خوبی نیز هست. اعتبار بیرونی شامل اعتبار محیطی و اعتبار آماری می باشد .
اعتبار آماری : اعتبار آماری به مناسب بودن حجم نمونه به حجم جامعه مربوط می شود .
اعتبار محیطی یا اکولوژیک :اعتبار محیطی مساله ی تجانس یا عدم تجانس جامعه ی آماری می باشد.
منبع: روش ها و تحلیل های آماری با نگاه به روش تحقیق. نویسندگان : دکتر ابراهیم حاجی زاده و دکتر محمد اصغری. سازمان انتشارات جهاد دانشگاهی .
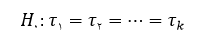
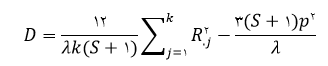

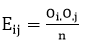
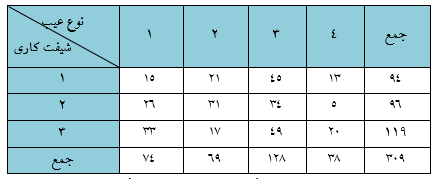

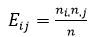
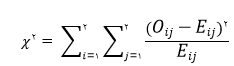
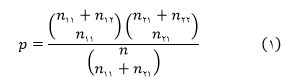
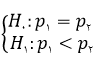






")
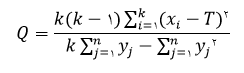
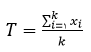



")
")


 ها پارامترهای مدل بوده و به کمک روش های مختلفی مانند روش حداقل مربعات و روش درستنمایی ماکزیمم برآورد می شوند.
ها پارامترهای مدل بوده و به کمک روش های مختلفی مانند روش حداقل مربعات و روش درستنمایی ماکزیمم برآورد می شوند. ها نیز جملات خطا نامیده می شوند و دارای توزیع نرمال با میانگین صفر و واریانس
ها نیز جملات خطا نامیده می شوند و دارای توزیع نرمال با میانگین صفر و واریانس هستند.
هستند.

 با می نیمم کردن معادله
با می نیمم کردن معادله
 نشان داده و با توجه به فرم ماتریسی تعریف شده در معادله (2) به صورت زیر محاسبه می شود
نشان داده و با توجه به فرم ماتریسی تعریف شده در معادله (2) به صورت زیر محاسبه می شود

 مقادیر برازش شده گفته می شود.
مقادیر برازش شده گفته می شود.







 ر پی بردن به انواع متداول مناسب نبودن الگو مفید است . اگر مدل برازش شده مناسب باشد این نمودار بایستی نسبت به نقطه ی
ر پی بردن به انواع متداول مناسب نبودن الگو مفید است . اگر مدل برازش شده مناسب باشد این نمودار بایستی نسبت به نقطه ی متقارن بوده و نقاط حول این نقطه به طور یکنواخت پراکنده شده باشند . این وضعیت ثابت بودن واریانس خطاها را نشان می دهد .این نمودار به طور معمول در سه شکل زیر دیده می شود :
متقارن بوده و نقاط حول این نقطه به طور یکنواخت پراکنده شده باشند . این وضعیت ثابت بودن واریانس خطاها را نشان می دهد .این نمودار به طور معمول در سه شکل زیر دیده می شود :



 را به صورت صعودی مرتب کرده
را به صورت صعودی مرتب کرده
















 و
و 
 و
و  است دارای
است دارای
























