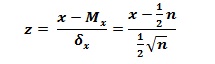در بسياري از علوم، تحقيقات بر اساس پرسشنامه صورت می گيرد. طراحي يك پرسشنامه خوب نيازمند تجربه و رعايت پاره اي قوانين مي باشد. اين نوشتار مطالب مرتبط با بهره برداري صحيح از يك پرسشنامه را در سر فصل عناوين ذيل ارائه مي نمايد:
1.1. پرسشنامه چیست؟
1.2. هدف از طراحي پرسشنامه
1.3. بيان مساله
1.4. تعيين جامعه آماري و انتخاب نمونه
1.5. اصول تدوين پرسشنامه
1.6. توزيع مقدماتي پرسشنامه
1.7. كنترل كيفيت پرسشنامه
1.8. توزيع نهائي پرسشنامه
1.9.تجزيه و تحليل آماري پرسشنامه
2. پرسشنامه چیست؟
پرسشنامه شامل دسته اي از پرسش ها ست كه برطبق اصول خاصي تدوين گرديده است و به صورت كتبي به افراد ارائه مي شود و پاسخگو بر اساس تشخيص خود جواب ها را در آن مي نويسد.
2.1. طبقه بندي بر اساس ماهيت پرسشنامه
- پرسشنامه باز
- پرسشنامه بسته
در پرسشنامه باز با سوالات باز روبرو هستيم. در اينجا پاسخگو مي تواند بدون محدوديت هر پاسخي را كه مد نظرش باشد در مورد آن پرسش بنويسد و يا در آن زمينه توضيح دهد. در اينگونه سوالات، اطلاعات دقيق تر، كامل تر و داراي ارزش بيشتر هستند ولي طبقه بندي و نتيجه گيري از آنها مشكل تر و به تجربه زياد نيازمند دارد.
در پرسشنامه بسته با پرسش هاي بسته مواجه هستیم. براي هر پرسش تعدادي گزينه و پاسخ انتخاب شده است كه فرد پاسخ دهنده بايد يكي از آنها رابه عنوان پاسخ بگزيند. هريك از پاسخ ها به گونه اي تنظيم شده است كه در عين منطقي بودن براي آن سوال از پاسخ مربوط به ديگر سوالات مجزا باشد. در اينجا پاسخ ها را مي توان به سرعت نوشت و تجزيه و تحليل و طبقه بندي پاسخ ها نيز ساده تر است اما اطلاعات به دقت و كاملي پرسش نامه باز نيست.
2.2. انواع پرسشنامه از لحاظ اجرا عبارتند از:
- پرسشنامه به طريق رو در رو
- پرسشنامه تلفني
- پرسشنامه پستی
- پرسشنامه رایانه ای
- پرسشنامه پست الکترونیکی
- پرسشنامه اینتنرنتی یا صفحات وب (لینک نمونه این پرسشنامه)
2.3. انواع پرسشنامه از لحاظ محتوای سنجش شده عبارتند از:
- پرسشنامه آگاهی سنجی Survey of Knowledge
- پرسشنامه نگرش سنجی Survey of Attitude
- پرسشنامه عملکرد سنجی Survey of practice
3. هدف از طراحي پرسشنامه
- تهیه فهرستی از هدف هایی است که پژوهشگر قصد دارد به کمک پرسشنامه به آنها برسد.
- داشتن درک روشنی از آنچه که باید حاصل شود
- به چه نوع اطلاعاتی نیاز داریم
- با این اطلاعات چه کارهایی می توانیم انجام دهیم
- چگونه هر سؤالی در پرسشنامه در رسیدن به این هدف به ما کمک می کند
- روش های تجزیه و تحلیل اطلاعاتی که پس از اجرای پرسشنامه جمع آوری می شوند چيست؟
4. بيان مساله
4.1. What is the problem
4.2. به دنبال چه هستيد؟
4.2.1. توصیف رفتار يا
4.2.2. طرز تفکر يا
4.2.3. یک احساس ویژه یا
4.2.4. آزمون رابطه بین دو یا چند متغیر
5. تعيين جامعه آماري و انتخاب نمونه
الف) در تعیین جامعه آماري به اين نكات توجه داشته باشيد:
5.1. اهمیت موضوع
5.2. قابلیت تعمیم پذیری
5.3. علاقه پژوهشگر
5.4. منابع اطلاعاتی
يك جامعه آماري مي تواند شهرک، شهر، استان، کشور، منطقه آموزشی واحد نظامی یا زیر گروهی از واحدهای ذکر شده نظیر گروه های قومی، مذهبی، سنی و شغلی باشد. توجه داشته باشيد به علت وسعت زیاد جامعه موردنظر، همیشه مطالعه تمام آن مقدور نیست و بعلاوه برای توصیف ویژگی های جامعه موردنظر و آزمون فرضیه در مورد آن نیازی به مطالعه تمام اعضای جامعه نیست. فلذا به انتخاب نمونه ای از اعضای جامعه که معرف و نماینده واقعی آن باشند اقدام می نمائيم.
ب) در تعیین نمونه آماري به اين نكات توجه داشته باشيد:
5.5. در تعيين حجم نمونه از فرمول ها و معيار هاي آماري استفاده كنيد.
5.6. توجه داشته باشيد بيشترين حجم نمونه قابليت تعميم نمونه به جامعه را محقق خواهد نمود.
5.7. براي مثال هنگاميكه شما مشغول طراحي يك پرسشنامه سنجش رضايت شغلي در يك شركت يا سازمان بزرگ مي باشيد مي توانيد با كمك واريانس و انحراف معيار جنس، سن يا تحصيلات تعداد نمونه مورد نیاز خود را بدست آورید.
5.8. روش نمونه گيري را مشخص كنيد: مثلا نمونه گيري خوشه اي چند مرحله اي
6. اصول تدوين پرسشنامه
در پژوهش هایی که از پرسشنامه استفاده می شود اعضا نمونه یا جامعه با پر کردن پرسشنامه و بازگرداندن آن به پژوهشگر در مصاحبه ای که خود آن را بر عهده داشته اند شرکت می کنند؛ به همین دلیل سؤال ها و راهنمایی های مربوط به آن باید به اندازه کافی روشن و قابل فهم باشد تا پاسخگو نقش مصاحبه کننده را نیز اجرا کند و بتواند افراد مورد نظر را در مشارکت ترغیب کند. دستورالعمل، سؤال ها و راهنمایی آن باید به گونه ای طرح شود که افراد مورد نظر را به ادامه همکاری و برگرداندن پرسشنامه علاقه مند نماید؛ این امر به خاطر عدم حضور مصاحبه گر واقعی برای توضیح بیشتر و تشویق پاسخ دهنده است.
بیشتر پرسشنامه ها حاوی مطالبی هستند که به منظور اندازه گیری متغیرهای وابسته و مستقل و ویژگی های موردنیاز تهیه و تدوین می شود دستورالعمل هایی که در تنظیم پرسشنامه الزامی هستند به شرح ذیل است:
6.1. سؤال های پرسشنامه باید ساده، روشن و دقیق باشند؛ زیرا هنگام پاسخگویی به آنها کسی جهت تعریف و توضیح حضور ندارد.
6.2. سؤالات پرسشنامه باید به صورت پاسخ بسته نوشته شود (يك گزينه از بين چند گزينه انتخاب شود) و بهتر است تعداد سؤال های پاسخ باز به حداقل ممکن برسد ولي حذف نشود. امکان دارد پاسخ هایی که به سؤالات باز داده می شود ناتمام و بی ربط باشند. ناخوانایی، غلط املایی و تفسیر پاسخ های باز از دیگر مشکلات سؤال های پاسخ باز می باشند.
6.3. به صورت اضافی و به خاطر جلوگیری از اشتباه از سؤالات گُزیده استفاده می شود. سؤال های گزیده به پرسش هایی گفته می شوند که گروه معینی از پاسخ دهندگان به آن پاسخ می دهند. برای مثال با مطرح کردن سؤالی درباره وضعیت تأهل در پرسشنامه می توان پاسخ دهندگان متأهل را شناسایی کرد و سپس پرسش های مربوط به فرزند، یا فرزندان، همسر و سایر موارد را مطرح نمود. هر سؤال گزیده به راهنمایی خاص خود نیاز دارد.
6.4. سؤال های مربوط به گذشته را در یک محدوده زمانی مشخص مطرح کنید در صورتی که قصد دارید درباره رفتار گذشته افراد اطلاعاتی کسب کنید، زمان مورد نظر را مشخص کنید. برای مثال این سؤال که چند بار مرتکب تخلفات رانندگی شده اید بسیار مهم است. عدم وجود محدوده زمانی مشخص در چنین سؤال هایی موجب می شود که افراد پاسخ های خود را به زمان های متفاوت نسبت دهند. لذا اطلاعاتی که در این گونه موارد بدست می آید در بهترین حالات فاقد انسجام خواهند بود و در بدترین شرایط به قدری مبهم اند که نمی توان بر اساس آنها دست به تحلیل زد. در محدوده های زمانی که چنین سؤال هایی به کار می روند به صورت زیر باید عمل شود که به صورت عبارت هایی همچون: در 5 سال گذشته، در یک سال گذشته، در یک ماه گذشته و یا اینکه اساساً سؤال کرد چه موقع برای اندازه گیری تعداد دفعاتی که رفتار افراد در آن ارتباط انجام شده است، اغلب محدوده زمانی کوتاه تر مناسب است زیرا پاسخ دهندگان نمی توانند وقوع رفتارهای خود را در زمان های طولانی به یاد آورند.
6.5. برای سؤال های حساس چارچوب مناسبی فراهم سازید گاهی اوقات پرسش هایی مطرح می شوند که ممکن است مغایر عقیده، باور، نگرش و مکاتب فکری باشند.
6.6. تعدادی از سؤال های پرسشنامه را به ویژگی های فردی و جمعیتی اختصاص دهید. این نوع سؤال ها که بر ویژگی هایی فردی تأکید دارند در قالب پرسشنامه ها مطرح می شود این پرسش ها از مواردی به این شرح تشکیل شده اند: سن، جنس، وضعیت تأهل، قوم و نژاد، تحصیلات، شغل، درآمد و گاهی اوقات مذهب، نوع مالکیت محل مسکونی، ترکیب خانوادگی.
6.7. سؤال های پرسشنامه باید یکی از جنبه های هدف و یا فرضیه صورت بندی شده را اندازه گیری کند به منظور تهیه و تنظیم پرسشنامه ای مناسب باید هر یک از سؤال های پرسشنامه هدفی را اندازه گیری کند؛ به عبارت دیگر سؤال باید به شیوه ای تنظیم شود که به کمک آنها بتوان اطلاعات لازم برای پاسخ دادن به سؤال های تحقیق یا آزمون فرضیه های صورت بندی شده جمع آوری کرد.
6.8. سؤال های پرسشنامه را با توجه به موضوع پژوهش در ارتباط با خصوصیت جامعه ای که پرسشنامه در آن اجرا می شود تعیین کنید. نظم و ترتیبی که سؤال های پرسشنامه بر اساس آن طرح می شود متفاوت است. ولی در اینکه جای هر سؤالی کجا باشد اتفاق نظری وجود ندارد. بعضی ترجیح می دهند که نکات مربوط به ویژگی های فردی و خانوادگی در ابتدای پرسشنامه و سؤال های حساس در آخر آورده شود و برخی عکس این عمل را انجام می دهند در واقع این پژوهشگر است که باید با توجه به بینشی که در مورد موضوع و جامعه ی پژوهشی خود دارد جای هر سؤال یا نظم و ترتیب آنها را تعیین نماید. چنانچه موضوع اهمیت قابل توجهی داشته باشد بهترین شیوه آن است که پرسش های مربوط به موضوع اصلی را در ابتدا بیاوریم تا بالاترین نسبت پاسخ دهی بدست آید.
6.9. صفحه اول پرسشنامه بایستي مربوط به نحوه ی پاسخگویی به سؤال ها باشد. و در آن به پرسش شونده اطمينان دهيد كه پاسخ هاي وي و اطلاعاتي كه در اختيار شما قرار مي دهد محرمانه تلقي خواهد شد.
6.10. هيچگاه در يك پرسش دو موضوع را مورد پرسش قرار ندهيد زيرا پرسش شونده ممكن است پاسخ متفاوتي به هر يك از سوال ها داشته باشد.
6.11. در طراحي سوال ايده خودتان و يا به عبارتي پاسخ خودتان را به پرسش شونده ديكته نكنيد. بعض سوالا ها طوري طراحي ميشوند كه پاسخ مشخصي دارند كه مفيد نيست.
6.12. از صفحه آرائي، چيدمان شكيل و فونت هاي مناسب و درشت براي طراحي پرسشنامه استفاده كنيد.
6.13. در پرسش هاي بسته مي توانيد از طيف ليكرت براي پاسخگوئي استفاده كنيد.
6.14. پرسشنامه را جذاب کنید. یکی از راه های رسیدن به این هدف چاپ پرسشنامه است.
6.15. پرسشنامه را صفحه بندی کنید.
6.16. سؤال های پرسشنامه را تا حد ممکن به شکل ساده طرح کنید به نحوی که پاسخگویی به آنها آسان باشد.
6.17. در ابتدا و انتهای پرسشنامه، نام و نام خانوادگی و آدرسی را که پرسشنامه به آنجا فرستاده شود ذکر کنید.
6.18. نحوه پاسخگویی به سؤال ها را خیلی ساده و با حروف درشت ذکر کنید.
6.19. در ابتدای هرنوع سؤال یک مثال مطرح و نحوه پاسخگویی به آن را مشخص کنید.
6.20. سؤال های پرسشنامه را براساس نظم منطقی مطرح کنید.
6.21. در ابتدای پرسشنامه سؤال هایی را مطرح کنید که جالب هستند.
6.22. در پرسشنامه هایی که خیلی طولانی هستند سؤالات مهم را در آخر پرسشنامه نیاورید.
6.23. از به کاربردن کلماتی که پاسخ دهندگان نسبت به آنها حساس هستند خودداری نمایید.
6.24. در هر سؤال اطلاعات را به طور کامل بیان کنید به نحوی که سؤال برای پاسخ دهنده معنی دار باشد.
6.25. طول پرسشنامه بر دقت پاسخگویی تأثیر دارد بنابراین در صورت امکان پرسشنامه را مختصر مطرح کنید. به عبارت دیگر در پرسشنامه فقط سؤال هایی را مطرح کنید که در جهت رسیدن به هدف های پژوهش مورد نیاز هستند.
7. توزيع مقدماتي پرسشنامه
پس از تدوین پرسشنامه و قبل از سنجش گسترده نخستین مرحله ارزيابي مقدماتي پرسشنامه است. زيرا ممكن است پرسشنامه نياز به بررسي مجدد، حذف از تعدادي از سوالات و يا افزودن سوالت جديد بر مبناي اطلاعات دريافتي از پرسش هاي باز باشد.
پس لازم است پیش نویس پرسشنامه قبل از اینکه به صورت نهایی تهیه و تنظیم شود چندین بار و از دیدگاه های مختلف بررسی شود. "دِیلی مَن" پیشنهاد می کند که پرسشنامه قبل از اجرا به صورت آزمایشی برای سه گروه زیر اجرا گردد:
7.1. گروهی از افراد جامعه که قصد دارید که یافته های پژوهش را به آنها تعمیم دهید.
7.2. کسانی که نتایج بررسی بوسیله آنها مورد استفاده قرار می گیرند مانند نهادهای اجرایی، مدیران سازمان ها و ....
7.3. صاحب نظران و متخصصانی که در تهیه و تنظیم پرسشنامه تبحر و تجربه دارند
معمولا در اين مرحله پرسشنامه بين خبرگان و يا نمايندگان اقشار مختلف نمونه آماري صورت مي پذيرد. و بر اساس تجربه بايستي حداقل 10 الي 15 درصد نمونه آماري را پوشش دهد.
8. كنترل كيفيت پرسشنامه
موضوع کنترل کيفيت نتايج يک پرسشنامه دامنه وسيعی از موضوعات مختلف را در بر می گيرد. اگر پرسشنامه را مانند يک آزمون فرض کنيم، به طور کلی می توان گفت يک آزمون خوب بايد از ويژگی های مطلوبی مانند عينيت، سهولت اجرا، عملی بودن، سهولت تعبير و تفسير، روايی و پايايی برخوردار باشد تا به نتايج درستی منجر شود. در بين اين ويژگی ها روائی و پايائی از اهميت بيشتری برخوردارند.
8.1. اعتبار و روايي (Validity)
روايی پرسشنامه عبارت است از توانايی ابزار مورد نظر در اندازه گيری صفتی که پرسشنامه برای اندازه گيری آن طراحی شده است و شامل روايی صوری، روايی محتوی، روايی سازه، روايی پيش بينی و .... می باشد. در حقيقت پرسشنامه يک ابزار اندازه گيری است که قرار است ويژگی هايی از يک جمعيت را اندازه گيری کند. سوال اين است که آيا اين ابزار اندازه گيری که برای ارزيابی يک ويژگی در جامعه (مانند تعهد سازمانی) طراحی شده است به چه ميزان می تواند اين ويژگی را اندازه گيری کند. هر قدر سوالات پرسشنامه ويژگی های مورد نظر را بهتر بسنجند، پرسشنامه دارای روايی بيشتری است. به طور کلی آزمونی دارای روايی است که برای اندازه گيری يک ويژگی کافی و مناسب باشد.
8.2. پايائي (Reliability)
يک سوال اساسی ديگر در مورد پرسشنامه يا هر آزمون ديگری اين است که اين ابزار اندازه گيری در شرايط يکسان تا چه اندازه نتايج يکسانی بدست می دهد؟ به عبارتی اگر آزمونی را در شرايط يکسان چند بار تکرار کنيم، تقريبا نتايج يکسانی داشته باشد. به طور کلی پايائی يک وسيله اندازه گيری، عمدتا به دقت و کيفيت نتايج حاصل از آن اشاره می کند. يا می توان گفت پايائی به دقت، اعتماد پذيری، ثبات يا تکرار پذيری نتايج آزمون اشاره دارد. برای اندازه گيری پايائی يک پرسشنامه شاخصی به نام ضريب پايائی وجود دارد. اين ضريب به اشکال مختلفی محاسبه می شود و مقدار آن بين صفر و يک در نوسان است. اين ضريب هر مقدار به يک نزديک تر باشد، پرسشنامه از پايايی بيشتری برخوردار است.
8.3. رابطه روايي و پايائي
رابطه بين روايی و پايائی را می توان چنين بيان کرد که يک آزمون بايد پايا باشد تا بتواند روا باشد. اگر آزمونی در هر بار اجرا روی تعدادی نمونه نتايج مختلفی بدست دهد، آن آزمون يک آزمون پايا نخواهد بود و در واقع هيچ چيز را به درستی اندازه نخواهد گرفت و اگر يک آزمون چيزی را به درستی اندازه گيری نکند، هيچ اطلاعات مفيدی به ما نخواهد داد. برای مثال يک آزمون رياضی برای اندازه گيری محتوا و هدف های درس تاريخ، روا (مناسب) نيست. اما اين آزمون می تواند مطالب رياضی را که اندازه می گيرد با دقت (به طور پايا) اندازه گيری کند. پس برای اين که يک آزمون روا باشد بايد نخست پايا باشد. يعنی پايايی شرط روايی است اما روايی برای پايايی ضروری نيست.
8.4. روش هاي تعيين پايايي
روش های تعيين پايايی متنوع اند که به پاره ای از آنها در زیر اشاره می شود:
8.4.1. روش آلفای کرونباخ (Alpha) برای مشاهده روش همبستگی درونی در پايايی يک پرسشنامه
8.4.2. روش دو نیمه کردن (Split-Half) برای مشاهده روش همبستگی درونی در پايايی يک پرسشنامه
8.4.3. روش گاتمن (Gattman) برای مشاهده حدود پائین و بالای روائی
8.4.4. روش موازی (Parallel) برای مشاهده پايايی دو فرم موازی از يک آزمون
8.4.5. روش موازی اکید (Strict Parallel) در اين روش برآورد اعتبار علاوه بر فرض يکسان بودن واريانس های دو آزمايش، تحت فرض يکسان بودن ميانگين ها نيز صورت می گيرد.
در استفاده از روش آلفای کرونباخ برای سنجش پایائی پرسشنامه محدوده مقادیر قابل قبول آلفا: بین 0.7 تا 1 عالی ، بین 0.4 تا 0.7 خوب و کمتر از 0.4 ضعیف محسوب مي شود.
8.5. روش هاي تعيين روائی
برای تعیین روائی محتوای یک آزمون از روش های نظری استفاده می شود که بیشتر آنها بر تجربه و نظر خبرگان استوار است. برای ارزیابی روائی سازه، از روش تحلیل عاملی ( Factor Analysis) استفاده می شود.
قابل ذكر است نرم افزار SPSS كليه امكانات و ابزار هاي لازم براي سنجش آلفاي كرونباخ و تحليل عاملي را دارا مي باشد.
چنانچه در زمينه سنجش آلفاي كرونباخ یا روش تحلیل عاملی در نرم افزار SPSS به راهنمائي نياز داريد، از این سایت مفید که متعلق به آقای میرزاده می باشد بازدید فرمائید. اینجا کلیک کنید.
9. توزيع نهائي پرسشنامه
پس از تدوین پرسشنامه و كنترل كيفيت اوليه تعیین چگونگی توزیع و جمع آوری پرسشنامه مطرح مي شود.
برای این کار دو روش متداول است:
9.1. تحویل پرسشنامه ها به پاسخ دهندگان به صورت مستقیم
9.2. پست کردن پرسشنامه ها.